How I took 3 million years off a client’s Disaster Recovery Time.
Imagine entering your data center to find it flooded, servers under water, and power out, breaking the business that relies on the data center. You don’t know what you’ve shipped. Who you’ve paid. Your next scheduled meeting.

CIO job opening
How long would it take you to recover? Do you know?
This nightmare was my new clients’ waking day. A sewer pipe had broke above their data center. They were unprepared and it took a painfully long time to for them to bring the business back.
On my first call with the client, after we finished joking about what sort of day that was, we reflected on the event as a harsh reminder of the importance of knowing your risk profile, capabilities, and business requirements and having the proper infrastructure, organization, governance processes, and Disaster Recovery Plan in place. And I was introduced to their new CIO—a replacement for the CIO in charge the day of the pipe breakage.
The new CIO wanted to know how exposed the business was and what they could do to close the gaps.
I suggested we do it quickly, if imperfectly. No traditional assessment. Not for this troubled enterprise.
Note: If you’re in the middle of an IT disaster, and that’s why you’re here, I suggest clicking here BREAK GLASS.
Traditionalists are not quick enough
for you.
The traditional consulting approach to IT risk identification, mitigation, and capability alignment to business requirements is a long slog. It’s a logically structured approach but unbearably extends the business’ risk exposure.
It’s what they teach in Consulting School.
To me, it borders on irresponsibility. Here is a quick sketch of it.

Traditional DR Assessment Approach
3 to 12 months analysis
Protracted risk exposure
The traditional approach is a logical series of assessment phases and acronyms. BIA … SPF … RA … FMEA … ALE … DR … DRP. It’s not a bad way to connect IT capabilities to business requirements, but it’s interminably slow and unnecessarily exposes people to risk.
For a small to medium enterprise ($1B - 10B), the Traditional Timetable can look like this.
· BIA ~2 months +
· RA, SPF, FMEA ~6 weeks to a 1 year +
· Dependency mapping ~3 months to 1 year +
· Strategy ~2 months +
· DR Architecture ~ 2 months +
· DR Plan ~ 2 months +
· DR Program Office ~ 1 months +
· Transform architecture/Risk Mitigation (initiation) ~ 2 months +++
Total: 1 year + to get started eliminating risks.
Here’s the approach:
Business Impact Analysis (BIA) to determine what you need to protect by identifying all your business processes and functions (a Process Map) and arriving at estimates of the Cost of Loss for each of those at varying times of the year, day, month, at multiple event durations. Risk Assessment (RA) to find the Single Points of Failure (SPF), perform a Failure Mode and Effects Analysis (FMEA), and assess site risks such as regional flooding, political upheaval, power, fire, and the like. The combined BIA and RA should produce Annualized Loss Estimates (ALE) that you use to derive the right level of budget and the right places to invest in Disaster Recovery. Rationally, you shouldn’t spend much more than your ALE and should not be constrained to spend significantly less. Dependency mapping to logically connect everything identified in the BIA to the physical hardware and people and processes that support it. And a strategy with options, scenarios, costs, milestone plans, and cash flows. Then, new designs for your infrastructure. Before we go further, let’s name this thing caused by a sewer break, meteor impact, earthquake, political upheaval, or epidemic; it is a Disaster. During said Disaster, we execute Disaster Recovery (DR). Following the traditional approach, having yet to do anything to reduce your risk, you will create a Disaster Recovery Plan (DRP), a set of instructions to use on the day of Disaster—who to call, which levers to pull—to implement what you designed in your strategy and are soon going to spend to improve your architecture, organization, and staffing model.
Then you need to put together a DR Program Management Office (DRPMO) with specialists, governance, and a budget (if you don’t set up a DRPMO the money you spent on the above will be wasted in irrelevance within three years). And then (when it’s a bit like a group of three-year-old kids planning a game to play, “you be the pony and I’ll be the princess and then…”) you start transforming the architecture, mitigating risks, reducing your exposure.
A year is too long to sit around and do nothing. You need to short-cut the process and mitigate business risk now.
A background in DR.
Me. Cloud/SaaS DR at SAP (2019-2023), PwC’s Global Disaster Recovery Practice founder and lead (2010-2019), working with companies in critical industries and high visibility—companies from $112M to $100B mark, in industries as diverse as banking and finance, health care, nuclear energy, airlines, manufacturing and retail.
As part of this, building out a formidable team, I also wrote and delivered a multi-day DR training program that made people both effective DR consultants and prepped them for certification as Disaster Recovery Institute International (DRII) Certified Business Continuity Planners (CBCP).
I’ve spoken at forums like Information Systems Audit and Control Association (ISACA) general meetings and the Disaster Recovery Institute International’s World Conference.
Before PwC, I’d helped lead DR practices in other consultancies. Before that, as Senior Engineer at the world’s oldest and largest Dot-Com, I’d developed groundbreaking DR and High-Availability approaches.
Why I ran the practice.
The top three compelling events. Reasons people called me to talk DR.
• They had just experienced a massive IT disruption
• The board had hired them to replace a disgraced Executive sacked for an outage
• They’d been audited and couldn’t prove they were sufficiently prepared
They called out of fear, most often. But also.
• Concern that the business cannot survive catastrophic technology loss
• Regulations that require tested DR Programs
• A lack of visibility into current DR capabilities
• Customer and partner questions regarding the DR Program
• Suspicion that the money spent on DR too much; not justified by the value of the business processes and functions being protected
• There was a DR program, but it was left fallow for years without investment and is now irrelevant and worthless
In no case was DR my only job. I find other things more interesting, but risk is real; Disaster Recovery is a business imperative.
The basics.
Disaster.
Business Objectives.
Disaster Recovery.
Disaster. Loss of IT capability where standard operating procedures would put recovery outside of acceptable business disruption. Think meteor. Earthquake. War. Flood.
But it’s usually more banal.

The disaster cause is usually a common event.
And the cause is irrelevant.
Disaster and Disaster Recovery are specific to recovering technology following massive hardware loss or failure.
They are related to, but distinct, from Availability.
Disaster is a single significant loss of IT service from any cause. It’s always a failure in people, process, or technology.
Don’t get hung up on what could cause your Disaster. It doesn’t matter what causes the outage—not in terms of recovery—it matters what you can do when it strikes. That’s your opportunity. Recover the business, no matter what.
That said, here are real-life Disaster examples.
• Sewage floods a data center and stops production lines, shipping, AP/AR
• A regional storm disrupts power for days
• A storage device fails and takes TV subscriber information with it
• Tornadoes level a data center supporting outsourced 911 calls
• A piece of network hardware fails and corrupts all critical operational data for a country’s essential infrastructure
• Meteor shower takes out infrastructure in the tundra
• A sinkhole swallows a data center in the Southwestern United States
The Disaster is not the IT outage.
The Disaster is the business outage.
It’s a business problem.
Know what the business needs.
The CIO’s challenge is meeting the business needs. The way we shape the business needs for IT and communicate them to IT is to set Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO) for each critical and sensitive business process.

Objectives = maximum acceptable business losses
Of Money, Safety, and Reputation.
The CIO’s job is to ensure that the technology for each business process is available within its RTO and RPO. And not necessarily sooner (as sooner, counterintuitively, can increase Disaster Recovery failure risk and the Cost of Loss/ALE.)
Disaster Recovery is a response to the inevitability of catastrophic technology disruption. It mitigates the disruption’s impact on finances, reputation, or safety. Disaster Recovery acknowledges that disruption is inevitable but that minimizing the impact and abbreviating the outage to business tolerances is possible.
Be quick.
Quicker than traditionalists.
There are things in business far more interesting than Disaster Recovery preparation. Things that generate stakeholder and shareholder value.
When pushed against the wall, we do DR capability development fast to avoid distraction and disruption. The point is to hold focus on our core business.
Set high expectations.

30 days to action.
To risk mitigation.
This rapid approach drives out risk by zeroing in on significant gaps in infrastructure, organization, and process.
Drives capability development by insisting that the business define IT priorities.
Funds the program by correlating risk losses to levels of investment.
The image below shows where the approach is going. Connecting business needs to IT capabilities for Disaster Recovery. We are aligning investments in IT people, processes, and technologies to business requirements for the recoverability of critical functions and processes.
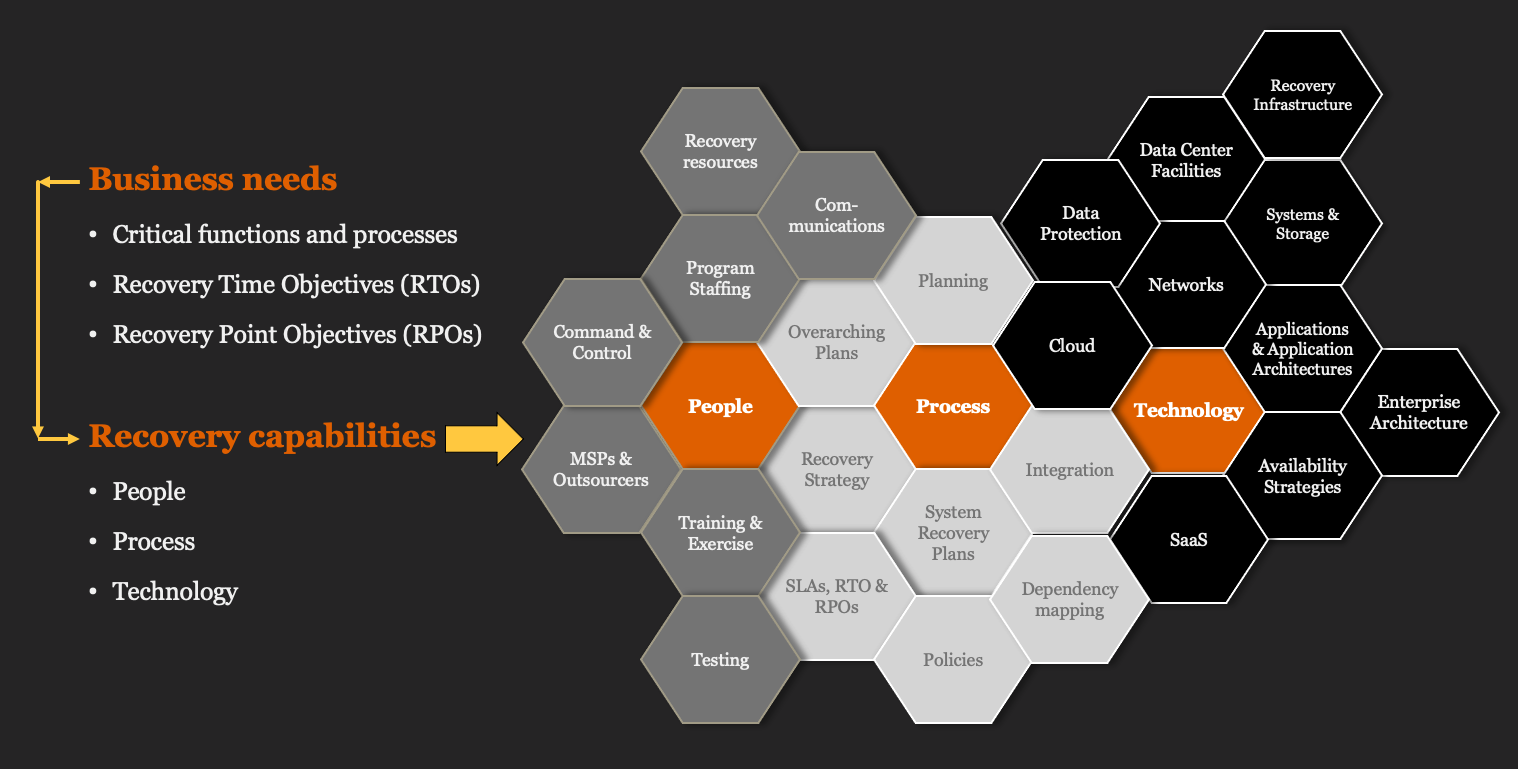
The route to alignment is straightforward.
We travel it with the intelligent people you already have. It is little about outside experts examining every little detail and drawing conclusions. It’s not about spinning every risk scenario and checking every wire. There’s no need for that. Your people know most of what you need and the risks in your operation and can figure out how to close the gaps. We will bring them together through a series of Disaster simulations.
Our journey: We discuss priorities and experiences cross-functionally with the executive leadership team. We review the available documentation for people, processes, and technology. We quickly study facilities and context. We conduct a series of Tabletop Exercises.

The Tabletop Exercises (TTX) is the crux of our approach.
Your people already have answers.
We simulate multiple Disaster scenarios with them. Tell stories. Coach them into being 80% right on the current state and what to do to shift capabilities into alignment with business needs.
If we’ve done the TTX well, we will know a lot about the business and IT.
Business needs and the Cost of Loss
Today’s IT capability for Disaster Recovery
Failure modes and risks for both operation and recovery
Opportunities
From this we can derive the Annualized Loss Estimate (ALE). We know gap between the business requirement for speedy Disaster Recovery and how far off IT capability is from the mark. We know what’s contributing to disaster declaration and we know what recovery processes are chewing up time, preventing us from recovering the business.
And we know where we should invest, what we should invest, and in what order
We know our investment budget and targets based on the Annualized Loss Estimate (ALE)
We get IT working right away across people, process, and technology
Mitigating critical risks to avoid Disaster declaration
Taking steps to enable recovery on the inevitable day it happens despite our efforts
We have a short-term (3 month) plan and long-term (3 year) plan
We’ve answered the question we asked at the beginning. We know how long it takes to recover from an IT Disaster (due meteor, flood, political unrest, earthquake, fire, malicious employee, et al).
The TTX. A closer look
The TTX is a seminar-styled, structured, facilitated walk-through of Disaster scenarios. Business and IT participates. Attendance is representative and up and down the vertical.
Preparation is the key to its efficiency and efficacy. Done well, it will deliver a treasure trove of data, information, insights, and cross-functional understanding.

The whole business attends.
It’s a business thing.
Start with donuts. Serve coffee. Warm people up. Let them say hello to each other.
It always starts with coffee, donuts, and speeches. Then we work.
I usually start with something like, “A meteor strikes your data center. What do you do? Does it matter? How long does it take to get the business running again if it stops business?”
And we discuss a bit. Typically, I have people seminar in cross-functional break-out teams for a few minutes, with a structured questionnaire, and then reconvene for discussion and the next prompt.
“New scenario. The data center is dark. The whole region is dark. No phones. No email. No Internet. No ERP.”
“In the first hour, does it matter?”
Go to break-out teams, return, discuss, and next prompt.
“Let’s assume power is restored everywhere but your data center. Some strange misconfiguration by the utility in a transformer. They don’t have an ETA yet.”
Go to break-out teams, return, discuss, and next prompt.
“What matters now? Are we losing money yet? Are we impacting safety or our reputation?
“In the second hour, what starts to be missed?
“If the office is non-productive because of a loss of IT, what are the most expensive process disruptions? Will there be fines? Does it matter if it’s the start or the middle of the month?
Go to break-out teams, return, discuss, and next prompt.
And continue in this fashion, at four-hour intervals until you get to a day. And then stretch it into a few days. Then let them know all the hard disks in the data center have been destroyed by a flaw in the fire suppression system (a real issue caused by the frequency of some sprinkler heads that inexplicably went off when the power spiked for a moment and then shut down).
Build the story.
Map critical business processes and functions
Identify those process and function dependencies on IT
Assess the impact/one-time Cost of Loss of those functions and processes over time
Arrive at working RPOs and RTOs for critical functions and processes
Uncover risks to availability and recoverability
Determine current Recovery Time Capabilities (RTC) and Recovery Point Capabilities (RPC)
Assess gaps in RTC and RPC against business-defined RTO and RPO
We conduct a Hot Wash and produce an After Action Report (AAR).
Keep going until you've recovered.
TTX rules and guiding principals.
We trust that we will get most things right
We accept we will get some things wrong
We do not let perfection get in the way of risk mitigation and capability development
We do not get wrapped around the axle discussing what could cause a Disaster—we accept Disaster is always an option and that we cannot and need not identify or mitigate all the ways to get there or think the TTX disaster scenario is true-to-life
We aim for precision so we can weigh priorities, make rational decisions
We do not strive for accuracy but to be mostly correct in relative values
We trust that the business mostly knows what's essential without the encompassing scope, strenuous pushback, and testing of full mapping efforts and a thorough BIA
After the TTX's. The team huddles to produce the deliverables for stakeholders and implementers.
Critical Process Maps, Business Dependency Maps, a BIA, and ALE
Short-term and long-term risk mitigation and capability development plans
We table a complete BIA and its attendant processes, the traditional approach, but do not forget it—what doesn't get done goes in our DRPMO's portfolio and capability development schedule
Enter the TTX sessions and AARs into Compliances' Global Risk Register/database
It does help to have an experienced TTX leader with DR knowledge to organize, plan, and execute the sessions. They are available for hire if you need to get your own.
Real-life finding things in the sewer leak.
Week 2, we reduced their recovery time by 3 million years.
With my clients drying their flooded data center, I launched into the 30-day rapid capability development process, working closely with the CIO, the business, and IT.
In the first session, we found that their recovery time from a total loss was about 3 million years.
The only decryption key for their backup tapes was in the data center, and if the machine holding the key was lost in an event, we would need to crack the encryption on their tapes. Estimates using the compute power available, then put that at a little over 3M years.
For an investment of $500, we secured a second encryption device, which we put offsite with a backup copy of the key. First major risk to recovery, done.
Week 3, we took recovery time down another 4 weeks
We determined that their sole ERP system was in the flooded data center (happily, not wrecked in the last incident). The loss of the ERP system would precipitate a minimal 4-week recovery, as equipment would need to be sourced, ordered, installed, and configured, and then restoration made from backup tapes. The ERP system stored their production schedules, shipping, AP/AR … all their business. A 4-week recovery may have been as existentially profound as a 3-million-year recovery. We determined that the ERP system was redundant within the data center, and we split the system and moved the standby half to another facility about 35 miles away. It was not a perfect solution, but it meant that in most disasters, at least the loss of their primary data center, they could recover their ERP in a mere 4 hours. As a manufacturer, they could now survive as a business through a significant Disaster.
We found critical gaps in under a month.
Mitigated the risks within 90 days.
Collectively, we improved their risk profile and recovery capabilities monumentally in nearly no time and set them on a course to sustainable high resilience. There was other work to do, but we had moved the company to solid ground with a precise and minimal capital investment. In 90 days, they’d gone from a critical Recovery Point Capability of 3 million years to 4 hours.
How much did the consulting cost?
The rapid approach was 1/5th the cost of the traditional approach. If you want more detail, let’s talk.
Check my Contact page for details on how to set a call.
Where this doesn’t work.
This Disaster Recovery capability development approach works across industries and can be applied to availability and Business Continuity. As to industries, I’ve found the same general approach applies to airlines, nuclear energy, banking, manufacturing, software, Software as a Service (SaaS), cloud services providers, government agencies, retail, construction, and every other business I’ve worked with.
In some cases, such as in the airline, energy, and SaaS businesses—incredibly robust operational availability preparedness can make up for minimal Disaster Recovery preparedness—but sadly, this is true in rare cases. The approach in these industries should differ, but there isn’t always enough operational excellence to support it.
Where else does it work?
Though I first used this for Disaster Recovery, I’ve employed it in other areas. For instance, troubleshooting global financial reporting processes for a largeretailer. And, to improve operational incident response and drive up NPS in a significant SaaS and services company.
Is this for you?
Here are some questions I commonly ask to help gauge, off-the-cuff, whether the existing DR program is viable or likely to fail:
• Do you have a current Business Impact Analysis?
• Was the Business Impact Analysis conducted with the business, or just with IT?
• What is your recovery strategy?
• Is your primary data center in the same location as your core technical team?
• Do you have a documented enterprise DR plan?
• When did you last test your DR strategy?
Yes answers to any of those is concerning.
IN CASE OF DISASTER BREAK GLASS

What if disaster struck today, and you didn’t have people, processes, and technology in place?
Use your judgement. See Disclaimers
Once you have people to safety, you can consider the below.
Step 1: Get people to safety. Phone emergency services.
Use your judgement.
Here are generic suggestions. You’ll need to tailor them to your situation and needs.
Step 2: Start a stopwatch (you’ll need to know the time when you’re communicating to your stakeholders, and sorting things out afterward for continuous improvement)
Step 3: Put someone in charge—the Incident Commander (IC)—a tech-savvy middle-manager respected up and down the organizational hierarchy
Step 4: Get out of the newly anointed Incident Commander’s way
Then the Incident Commander can:
Assemble a team
Assess the safety
Assess the damage
Assess what you have to work with
Identify options
Identify business and IT priorities (IT priorities being those things that help it recover the business)
Identify low hanging fruit
Estimate level of effort and assess available staffing model
Estimate recovery time
Plan recovery of operations and start thinking about how you’ll return to normal
Decide what you’re doing
Form repair squads (IT leader’s responsibilities)
Execute in sprints
Communicate, but let people get to work
Here’s what the Incident Commander’s ad hoc team can look like.
Two C-Suite executives to form a decision-making quorum with the IC
A note taker that records decisions and times
A safety officer—maybe someone from HR
A Public Relations (PR) person to communicate with the board, company, customers, and street
A communications person (Comms) to broker communication for the IC and PR
People assigned to Comms to staff phones and find phone numbers
Communications are all between the CM and PR
An IT leader who forms a Damage Assessment Team (DAT) and Disaster Recovery Teams (DRTs)
A business operations representative (just one)
A controller from Finance
Compliance person (probably someone from audit) to keep an eye on relevant compliance standards
You could call me during your disaster. I can advise. Your best choice for Incident Commander is someone who knows the organization and is trusted by it.

Best,
Robert Synak
PwC Global DR Practice Lead, 2010-2019
Insight, Principal and DR Consultant, 2003-2010
917-539-9423
#DisasterRecovery #ProcessImprovement #RiskMitigation
For more information
This publication is based in part on presentations the author has delivered to organizations such as the Information Systems Audit and Control Association (ISACA) and the Disaster Recovery Institute International (DRII), as well as over 15 years of thought leadership and practice around Disaster Recovery. Although it seems the IISACA link is no longer available, the DRII presentation link is below.
Disaster Recovery International. (2013, 5 June). Let's Get It Wrong Quickly. DRI International. https://drive.drii.org/tag/robert-synak/.
Additional Sources
PwC. (2023). PwC’s Global Crisis and Resilience Survey 2023. PwC. https://www.pwc.com/crisis-resilience.
Uptime Institute. (2022, June 8). Uptime Institute’s 2022 Outage Analysis Finds Downtime Costs and Consequences Worsening as Industry Efforts to Curb Outage Frequency Fall Short. Uptime Institute.
https://uptimeinstitute.com/about-ui/press-releases/2022-outage-analysis-finds-downtime-costs-and-consequences-worsening.
Disclaimers
While this publication offers general insights, it's essential to remember it's not a substitute for professional advice. Before making decisions based on the content here, seek out specific professional advice tailored to your situation. No representation or warranty (express or implied) is provided regarding the accuracy or completeness of the information contained in this piece. Robert Synak, any affiliated persons or organizations, along with affiliate members, employees, and agents, do not accept or assume any liability, responsibility, or duty of care for any consequences that may arise from actions or decisions made (or not made) based on this publication.
The views expressed here are Robert Synak’s, they are not presented to suggest they represent, or are endorsed or shared by, any organization or individual Robert Synak has been associated with, past or present.